Help us polishing the native migration
We are calling out for beta testing of the data migration that makes Projects eventually not need the auxiliary conversions to Git.
This article is intended for our early adopters. If your Heptapod instance was created at version 0.25 or later, it is unlikely that you have any concerned Project.
Background
In the dark ages of Heptapod, before HGitaly saw the light, Mercurial repositories were systematically synchronized to an internal Git repository that served as a view used by the Web application to present repository content. This allowed us to get a working prototype very quickly, but has lots of drawbacks, in user experience as well as in performance and server administration.
Since then, we've introduced native Mercurial projects, in which Mercurial repository content is exposed to the Web application by a separate service called HGitaly, pretty much in the same way that Git repository content is exposed to GitLab by the Gitaly service.
In version 0.25 (September, 2021), Heptapod has switched long ago to native Mercurial projects by default, but that affected only the project creation. In other words, projects that were created earlier than that are still based on the convertion from Mercurial to Git and have to be manually migrated to become native.
To go in-depth on these topics, see The road to fully native Mercurial in Heptapod.
Heptapod does ship with a data migration to make a Mercurial project native, but it is still deemed to be experimental and therefore not exposed in the Web UI. We've run it on the instances that we managed directly, of course, but there is only so much we can cover ourselves. The main objective of this post is to request feedback from the users community so that we can iron out the remaining problems and make it mainstream, hopefully by exposing it in the Web UI in version 0.38 or 0.39.
Data migrations are always a pain to develop and maintain, as it is very hard to cover all corner cases, especially with a data model so rich and interconnected as GitLab's. That is why we really need to get more feedback before taking the next step.
How to check if a Mercurial Project is native
The home page of a Project displays its Version Control System (VCS) type right next to its name.
You will see hg for a native Mercurial Project and hg (legacy) for a Project entirely based on conversions to Git.

Native Mercurial Projects display "hg" on their home pages.
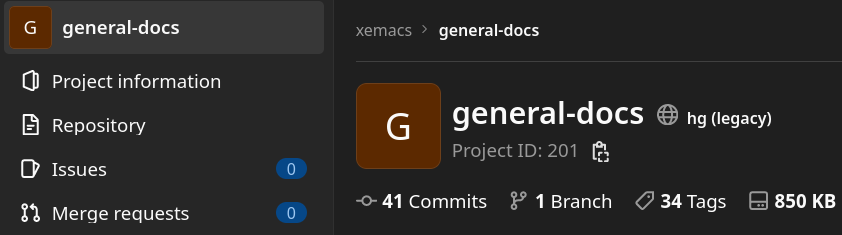
Legacy (hg-git based) Mercurial Projects display "hg (legacy)" on their home pages.
For some Systems Administrators, it might also be more convenient to query directly using SQL the vcs_type column of the projects table. The values are hg_git for legacy Mercurial Projects based on the inner conversion to Git and just hg for native Mercurial Projects. Guessing the value for Git projects is left to the reader.
For instance, here is the current breakdown of foss.heptapod.net:
# SELECT vcs_type, COUNT(*) FROM projects GROUP BY vcs_type ORDER BY vcs_type; vcs_type | count ----------+------- git | 13 hg | 146 hg_git | 318 (3 rows)
This example also discloses two interesting facts about foss.heptapod.net (see below for more details).
What to migrate
Please consider that all data migrations are at least mildly dangerous, ensure that your backups are in good shape and proceed gradually:
Start with small projects with a moderate amount of traffic, then ramp it up carefully, preferably after you get end-user feedback.
If you have legacy Mercurial Projects with tens of thousands of files and changesets, you may want to watch carefully how the HGitaly service behaves, as there are currently performance issues being addressed (see RHGitaly). Needless to say, subscribing to Octobus support can also help a lot at this scale.
The migration to native
What the migration is actually meant to do is to replace every occurrence of a Git commit hash by its corresponding Mercurial changeset hash (formally called Node ID).
Perhaps the most prominent relevant data are Issues, Merge Requests and Notes (comments), as they are partly due to user input. There are many more such references internally, notably in CI/CD objects, as the hash is the primary key used to address commits.
General properties
- The migration is at the time of this writing to be run from the command line, for a single project.
- The migration is not reversible. Once it has reached a certain stage, it will not rollback if an error occurs. Currently, this point of no return is set at the migration of Merge Requests: once that is done, there is no turning back.
- The migration is designed to be idempotent. The intent is that problematic data can be corrected by running a fixed version of the migration. Therefore, reporting on your errors is the way to have them fixed.
Running
The migration is available as the heptapod:experimental:hg_migrate_native Rake task. It takes one mandatory and two optional arguments:
- The first argument, is the numeric id of the Project to migrate
- The second argument is a boolean, defaulting to false. When set to true, it allows running the migration again if the Project has already been migrated.
- The third argument is the username to be recorded as the user that ran the migration. It defaults to root.
With the Omnibus and Docker images, one can run it as, e.g:
gitlab-rake heptapod:experimental:hg_migrate_native'[23]'
To run again after fixing a problem, that would be:
gitlab-rake heptapod:experimental:hg_migrate_native'[23,true]'
In case the instance is installed from source, replace gitlab-rake by bundle exec rake instead.
Checking for errors
The migration will list problematic content on stdout or stderr.
More details are available in the heptapod_native_migration_logs table.
Please also try and open the problematic content in a Web browser to help us assess the severity of the problem.
Making it mainstream
When we have enough feedback and undoubtely have corrected at least a few quirks, we will no sooner than in Heptapod 0.38:
- Allow Project Owners to run the migration from the Project Settings, alongside "Archive Project", "Transfer Project", etc.
- remove experimental from the Rake task name.
Later on, we'll allow the Rake task to run in bulk.
In the far future, we'll migrate the remaining last legacy projects automatically.
The state of native Mercurial on foss.heptapod.net
As it can be seen above, there are still lots of legacy Mercurial Projects on foss.heptapod.net, and that is perhaps a surprise, given that this instance is generally the most bleeding edge around, often running the latest release candidate.
So, of course it was the first to run the migration ever, and the Heptapod development Projects were among the first to go native. However, even over there, we need to be cautious:
- We host some large developement communities (PyPy notably). This means that some coordination has to be done.
- foss.heptapod.net has some of the largest Mercurial repositories of any Heptapod instance. The conversion to Git is by orders of magnitude the main bottleneck in pushes. On the other hand, removing it places the load on the relatively young HGitaly service. We've reached the limits of HGitaly on foss.heptapod.net some time ago – this was the primary motivation for the development of an ultra fast, lean and non-blocking pure Rust implementation: RHGitaly. We're now waiting for the likes of FindCommit and TreeEntry to land in production to proceed further.
Final words
Thank you for reading so far!
We're truly excited about your Projects finally ditching their Git crutches. Also, we realize that all of this is extra work for our early adopters, and we thank you heartily, as Heptapod probably wouldn't exist without you.